The Eberhard-Green-Manners Sum-free Subset Theorem, and `What is Sum-free(13)?’
The first research level math problem I seriously worked on (without much success) was the sum-free subset problem. A sum-free set (in an additive group) is a set that contains no solution to the equation 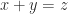
Theorem: (Erdős, 1965) Let A be a finite set of natural numbers. There exists a sum-free subset 
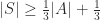
The natural problem here is to determine how much one can improve on this result. Given the simplicity of the proof, it seems that one should be able to better. However, the best result to date is 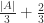
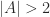
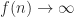
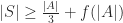

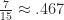

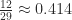
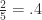
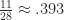
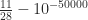

About a month ago Sean Eberhard, Ben Green and Freddie Manners solved this problem, showing that
In the wake of this breakthrough on the upper bound problem, I thought I’d take this opportunity to highlight a toy case of the lower bound problem.
Definition: For a natural number 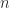
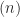
Thus by Bourgain’s theorem we have that Sum-free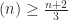
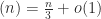
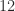

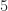

Conjecture: Sum-free
While the asymptotic lower bound problem (showing that there 
|
Bourgain’s lower bound on Sum-free |
Best known upper bound on Sum-free |
Upper bound set example |
| 1 | 1 | 1 |  |
| 2 | 1 | 1 | 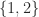 |
| 3 | 2 | 2 | 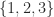 |
| 4 | 3 | 3 | 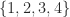 |
| 5 | 3 | 3 | 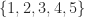 |
| 6 | 3 | 3 |  |
| 7 | 3 | 3 | 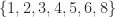 |
| 8 | 4 | 4 | 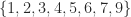 |
| 9 | 4 | 4 | 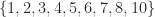 |
| 10 | 4 | 4 |  |
| 11 | 5 | 5 | 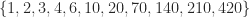 |
| 12 | 5 | 5 | 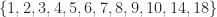 |
| 13 | 5 | 6 | 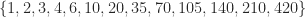 |
| 14 | 6 | 6 | 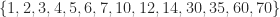 |
| 15 | 6 | 7 | 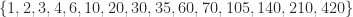 |
An Exact Asymptotic for the Square Variation of Partial Sum Processes
Allison and I just arxiv’ed our paper An Exact Asymptotic for the Square Variation of Partial Sum Processes.
Let 
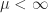
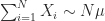
almost surely. Without loss of generality, one can assume that 
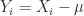
![\mathbb{E}\left[|X_{i}|^2 \right] = \sigma^2 < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%7CX_%7Bi%7D%7C%5E2+%5Cright%5D+%3D+%5Csigma%5E2+%3C+%5Cinfty&bg=fff&fg=222&s=0&c=20201002)

where the constant 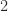


Theorem Let 
![\mathbb{E}\left[|X_{i}|^{2+\delta}\right] < \infty](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%7CX_%7Bi%7D%7C%5E%7B2%2B%5Cdelta%7D%5Cright%5D+%3C+%5Cinfty&bg=fff&fg=222&s=0&c=20201002)
![[N]](https://s0.wp.com/latex.php?latex=%5BN%5D&bg=fff&fg=222&s=0&c=20201002)
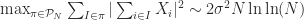
Choosing the partition 
![J=[1,N]](https://s0.wp.com/latex.php?latex=J%3D%5B1%2CN%5D&bg=fff&fg=222&s=0&c=20201002)
An interesting problem left by this work is deciding if the moment condition
Theorem Let 
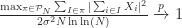
The millennium problems and football
From a discussion thread on CNN’s story Footballer: ‘Are you OK with destroying a kid’s brain for this game?’:

How to leak on key updates
Leakage resilient cryptography is an exciting area of cryptography that aims to build cryptosystems that provide security against side channel attacks. In this post I will give a nontechnical description of a common leakage resilient security model, as well as describe a recent paper in the area with Allison Lewko and Brent Waters, titled “How to Leak on Key Updates”.
Review of Public Key Encryption
Let us (informally) recall the definition of a public key cryptography system. Alice would like to send Bob a private message 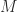
1) Eve has limited computational resources,
2) certain computational problems (such as factoring large integers or computing discrete logarithms in a finite group) are not efficiently solvable, and
3) we allow Alice and Bob to use randomization (and permit security to fail with very small probability).
More specifically, a public key protocol works as follows: Bob generates a private and public key, say 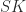
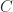
Leakage Resilient Cryptography and our work
In practice, however, Eve may be able to learn information in addition to what she intercepts over Alice and Bob’s public communications via side channel attacks. Such attacks might include measuring the amount of time or energy Bob uses to carry out computations. The field of leakage resilient cryptography aims to incorporate protection against such attacks into the the security model. In this model, in addition to the ciphertext and public key, we let Eve select a (efficiently computable) function 

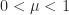
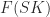
Moreover, we allow Eve to specify a different function 


There has been a lot of interesting work on this problem. In the works of Brakerski, Kalai, Katz, and Vaikuntanathan and Dodis, Haralambiev, Lopez-Alt, and Wichs many schemes are presented that are provably secure against continual leakage. In these schemes, however, information about the secret key is permitted to be leaked between updates, but only a tiny amount is allowed to be leaked during the update process itself.
In our current work, we offer the first scheme that allows a constant fraction of the information used in the update to be leaked. The proof is based on subgroup decision assumptions in composite order bilinear groups.
Adam Smith on mathematicians (circa 1759)
I recently came across the following passage regarding the mathematical profession from Adam Smith’s influential work The Theory of Moral Sentiments that I thought others might find interesting:
Mathematicians, on the contrary, who may have the most perfect assurance, both of the truth and of the importance of their discoveries, are frequently very indifferent about the reception which they may meet with from the public. The two greatest mathematicians that I ever have had the honour to be known to, and, I believe, the two greatest that have lived in my time, Dr Robert Simpson of Glasgow, and Dr Matthew Stewart of Edinburgh, never seemed to feel even the slightest uneasiness from the neglect with which the ignorance of the public received some of their most valuable works. The great work of Sir Isaac Newton, his Mathematical Principles of Natural Philosophy, I have been told, was for several years neglected by the public. The tranquillity of that great man, it is probable, never suffered, upon that account, the interruption of a single quarter of an hour. Natural philosophers, in their independency upon the public opinion, approach nearly to mathematicians, and, in their judgments concerning the merit of their own discoveries and observations, enjoy some degree of the same security and tranquillity.
The morals of those different classes of men of letters are, perhaps, sometimes somewhat affected by this very great difference in their situation with regard to the public.
Mathematicians and natural philosophers, from their independency upon the public opinion, have little temptation to form themselves into factions and cabals, either for the support of their own reputation, or for the depression of that of their rivals. They are almost always men of the most amiable simplicity of manners, who live in good harmony with one another, are the friends of one another’s reputation, enter into no intrigue in order to secure the public applause, but are pleased when their works are approved of, without being either much vexed or very angry when they are neglected.
The entire text is available here.
Restriction estimates for the paraboloid over finite fields
Allison and I recently completed a paper titled Restriction estimates for the paraboloid over finite fields. In this note we obtain some endpoint restriction estimates for the paraboloid over finite fields.
Let 
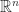


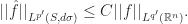
We note that the left-hand side is not necessarily well-defined since we have restricted the function 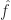



In 2002 Mockenhaupt and Tao initiated the study of the restriction phenomena in the finite field setting. Let us introduce some notation to formally define the problem in this setting. We let 




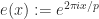






For a complex-valued function
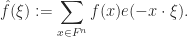
For a complex-valued function 


It is easy to verify that 

We define the paraboloid 




For a function 


For a complex-valued function 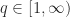
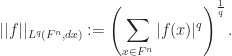
For a complex-valued function
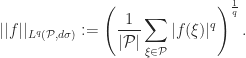
Now we define a restriction inequality to be an inequality of the form

where 

We will use the notation 
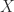


Mockenhaupt and Tao solved this problem for the paraboloid in two dimensions. In three dimensions, we require 

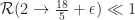
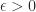

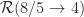



In this note we remove the logarithmic losses mentioned above. Our argument begins by rewriting the 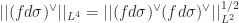
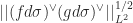
To obtain estimates for arbitrary functions 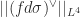
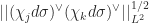


Our method yields the following theorems:
Theorem For the paraboloid in 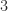
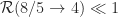
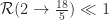
Theorem For the paraboloid in 




We recently learned that in unpublished work Bennett, Carbery, Garrigos, and Wright have also obtained the results in the
An improved upper bound for the sum-free subset constant
I recently arXiv’ed a short note titled An Improved Upper Bound for the Sum-free Subset Constant. In this post I will briefly describe the result.
We say a set of natural numbers 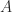
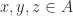
Theorem Let 
The proof of this theorem is a common example of the probabilistic method and appears in many textbooks. Alon and Kleitman have observed that Erdős’ argument essentially gives the theorem with the slightly stronger conclusion 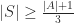





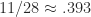
Sets of large doubling and a question of Rudin
Update (May 2, 2010): After posting this preprint, Stefan Neuwirth informed us that Rudin’s question had been previously answered by Y. Meyers in 1968. It appears that Meyers’ construction doesn’t, however, say anything about the anti-Freiman problem. Indeed Meyers’ set (and all of its subsets) contains a ![B_{2}[2]](https://s0.wp.com/latex.php?latex=B_%7B2%7D%5B2%5D&bg=fff&fg=222&s=0&c=20201002)


Allison Lewko and I recently arXiv’ed our paper “Sets of Large Doubling and a Question of Rudin“. The paper (1) answers a question of Rudin regarding the structure of 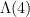
— Structure of
Before describing the problem we will need some notation. Let 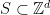



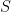
![{B_{h}[G]}](https://s0.wp.com/latex.php?latex=%7BB_%7Bh%7D%5BG%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
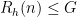




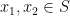

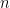
![{B_{2}^{\circ}[G]}](https://s0.wp.com/latex.php?latex=%7BB_%7B2%7D%5E%7B%5Ccirc%7D%5BG%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
Let 




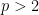
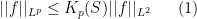
holds for all 

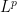
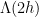

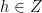
In this paper we show that the answer is no in the case of ![{B_{2}^{\circ}[2]}](https://s0.wp.com/latex.php?latex=%7BB_%7B2%7D%5E%7B%5Ccirc%7D%5B2%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
![{B_{2}[G]}](https://s0.wp.com/latex.php?latex=%7BB_%7B2%7D%5BG%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
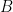

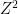

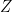
We have been unable to extend these results to 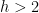
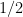

— Is there an anti-Freiman theorem? —
Let 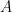


In fact, it isn’t hard to show that equality only occurs on the left if ![{B_{2}[1]}](https://s0.wp.com/latex.php?latex=%7BB_%7B2%7D%5B1%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
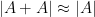
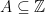



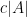


It is natural to ask about the opposite extreme: if 


![{B_2[G]}](https://s0.wp.com/latex.php?latex=%7BB_2%5BG%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
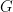
![{B_2[1]}](https://s0.wp.com/latex.php?latex=%7BB_2%5B1%5D%7D&bg=fff&fg=000000&s=0&c=20201002)

![{[1,n]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2Cn%5D%7D&bg=fff&fg=000000&s=0&c=20201002)

There are two ways one might try to fix this problem: first, we might ask only that 
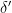



![{B^\circ_2[2]}](https://s0.wp.com/latex.php?latex=%7BB%5E%5Ccirc_2%5B2%5D%7D&bg=fff&fg=000000&s=0&c=20201002)
(Weak Anti-Freiman) Suppose that 
![{B^\circ_2[G]}](https://s0.wp.com/latex.php?latex=%7BB%5E%5Ccirc_2%5BG%5D%7D&bg=fff&fg=000000&s=0&c=20201002)

We conclude by showing that even this weaker conjecture fails. The constructions are the same as those used in the 

— A variant of the Erdös-Newman conjecture —
In the early 1980’s Erdös and Newman independently made the following conjecture: For every ![{B_{2}[G']}](https://s0.wp.com/latex.php?latex=%7BB_%7B2%7D%5BG%27%5D%7D&bg=fff&fg=000000&s=0&c=20201002)

Theorem 1 For every 

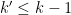
The dense model theorem
A key component in the work of Green, Tao, and Ziegler on arithmetic and polynomial progressions in the primes is the dense model theorem. Roughly speaking this theorem allows one to model a dense subset of a sparse pseudorandom set by dense subset of the the ambient space. In the work of Green, Tao, and Zeigler this enabled them to model (essentially) the characteristic function of the set of primes with (essentially) the characteristic function of a set of integers with greater density. They then were able to obtain the existence of certain structures in the model set via Szemerédi’s theorem and its generalizations.
More recently, simplified proofs of the dense model theorem have been obtained independently by Gowers and Reingold, Trevisan, Tulsiani and Vadhan. In addition, the latter group has found applications of these ideas in theoretical computer science. In this post we give an expository proof of the dense model theorem, substantially following the paper of Reingold, Trevisan, Tulsiani and Vadhan.
With the exception of the min-max theorem from game theory (which can be replaced by (or proved by) the Hahn-Banach theorem, as in Gowers’ approach) the presentation is self-contained.
(We note that the the theorem, as presented below, isn’t explictly stated in the Green-Tao paper. Roughly speaking, these ideas can be used to simplify/replace sections 7 and 8 of that paper.) (more…)
Halstead has a home!
Two weeks ago, not far from the UT math department, I found (or rather I was found by) a very friendly stray dog (pictured below). Since it was raining and the nearby streets were busy, I fed the dog and then brought it to Austin’s Town Lake animal shelter. The next day I called the shelter to learn that if the dog wasn’t adopted within three days it would likely be euthanized. With the help of several other members of the UT mathematical community, dozens of emails, phone calls, and Internet postings were made in an effort to find the pup a home. (In fact, the mathematical blogsphere was represented in these efforts.) (more…)

7 comments